The Potential of Clinical Data
Better Health and a More Efficient Healthcare System
Better Health and a More Efficient Healthcare System
Our daily lives generate millions of data points representing discrete moments that have the potential to be stitched together to power artificial intelligence algorithms, inform medical decisions at the point of, influence patient behavior, drive better outcomes, and predict and mitigate disease progression.
Clinical data is a tremendous resource capable of advancing healthcare’s digital revolution. However, the industry at large continues to be challenged by ineffectively deploying clinical data at scale. What is the potential of clinical data, and how can its full potential be unlocked to be more effectively leveraged as an asset?

Clinical data sourced from EHRs, labs and health information exchanges (HIEs) contain rich details on an individual’s health journey, including vital signs, test results, diagnoses, immunizations, and more. This unique data asset is not present in other data sources. These rich details are documented in real time, at the point of care and they are delivered in a variety of standard formats such as C-CDA documents, HL7v2 messages and, increasingly over time, as FHIR resources.
A great way to understand the richness of clinical data is by exploring the United States Core Data for Interoperability (USCDI). USCDI is a defined set of health data elements for patient data access and certain other exchange and interoperability use cases defined by the Centers for Medicare & Medicaid Services (CMS) and Office of the National Coordinator (ONC). Vocabulary standards such as RxNorm, Systematized Nomenclature of Medicine (SNOMED), LOINC, and International Classification of Diseases (ICD) are defined as part of the USDCI process. Certified HIT modules must support USCDI and make that data available in exchange standards, such as Fast Healthcare Interoperability Resource (FHIR®) or Consolidated Clinical Document Architecture (C-CDA).
“When doctors, underwriters, medical reviewers, and care coordinators get a timely and full picture of a person’s health in a form that fits into their tools and workflows, they make better decisions.”
Clinical data historically has resided within the confines of the EHR system. Increasingly, clinical data silos are breaking down, spurred by government regulation such as the 21st Century Cures Act, which champions the provision of clinical data to patients at their request and prohibits those entities and individuals that deliver care from interfering with, preventing, or materially discouraging the access to or exchange of electronic health information.
The healthcare industry generates and mines a growing amount of data every second to uncover valuable insights. Currently, healthcare accounts for around 30% of the world’s total data volume, totaling 28 zettabytes.1 Organizations can acquire data via multiple stewards such as HIEs, data aggregators, data retrieval services, and EHR vendors. For example, a payer can request data for its members from an HIE, which collects and consolidates such data from multiple providers in their region.
Typically, HIEs receive healthcare data in raw formats and either transmit them in their raw form to data users or after some degree of standardization to national standards. The challenge arises from the fact that there are approximately one hundred HIEs, making it difficult to obtain a comprehensive picture of a patient’s care. A patient may have a provider that sends data to one HIE, while hospital admission data may be reported to a different HIE. This is particularly common when patients receive medical care while traveling, for instance, a person residing in New York who requires medical attention while vacationing in California. To capture the patient’s complete care journey, data generated in both New York and California are necessary. Therefore, a strategy for accessing both HIE data sets is essential for a carrier to obtain the complete picture.
When doctors, underwriters, medical reviewers, and care coordinators get a timely and full picture of a person’s health in a form that fits into their tools and workflows, they make better decisions. When patients get this data, it encourages active participation, health literacy, and empowers them to better drive their own care. Better decisions and increased patient empowerment mean reduced costs and less exposure to financial risk as well as better clinical outcomes and consumer experience.
When analytics tools for population health, risk scoring, and quality measurement make use of clinical data—spanning across many sources and sites of care—there is enormous potential. When these sometimes inconsistent source data formats are normalized to national industry standards
that machines can ingest, the potential multiplies.
As clinical data has become ubiquitous and readily available, this rich resource has the potential to drive significant change for the industry. With more accurate results produced, downstream consumption of the data results in improved outcomes via more precise risk stratification, disease management, and care gap identification. These improvements in data precision and usability
“It can be a substantial challenge and investment to not only acquire and store clinical data but to transform and standardize clinical data at scale to tap into its potential.”
can mean higher reimbursement, faster workflows, and reduced operational costs. Operationalizing the insights found in clinical data has the potential to keep patients healthier and make the business of healthcare more efficient, less wasteful, and less costly.
However, doing so is easier said than done. It can be a substantial challenge and investment to not only acquire and store clinical data but to transform and standardize clinical data at scale to tap into its potential.

Here’s the reality: clinical data in its raw, native form is not ready for prime time. Availity and its affiliated companies have been in the business of standardizing and enriching clinical data for nearly a decade. We support some of the largest HIEs and national payer organizations across the country and have processed clinical data for more than one third of the U.S. population. Our clinical informatics team conducts data quality analyses as part of our deployments, including annual real-world data audits, and they routinely find that upwards of 50% of source clinical data cannot be used in its raw native form to achieve the potential described above.
A variety of factors contribute to data cacophony:
As part of Meaningful Use, CMS required that any certified EHR be able to generate a Continuity of Care (CCD) document, but that did not guarantee that information related to each defined clinical domain was recorded in a consistent or accurate way. For example, one clinician might dutifully use pulldowns and buttons in the EHR to properly document a vital sign whereas another might use a narrative note. Similarly, one clinician might document a flu shot in the EHR’s procedures section, and another might put it under immunizations. This may be sufficient for billing purposes, but for clinical utility, good is not good enough. This is because this lack of standardized documentation causes clinical data gaps in output CCDs, resulting in life and death decisions being made that are not based on the full picture of the patient’s health.
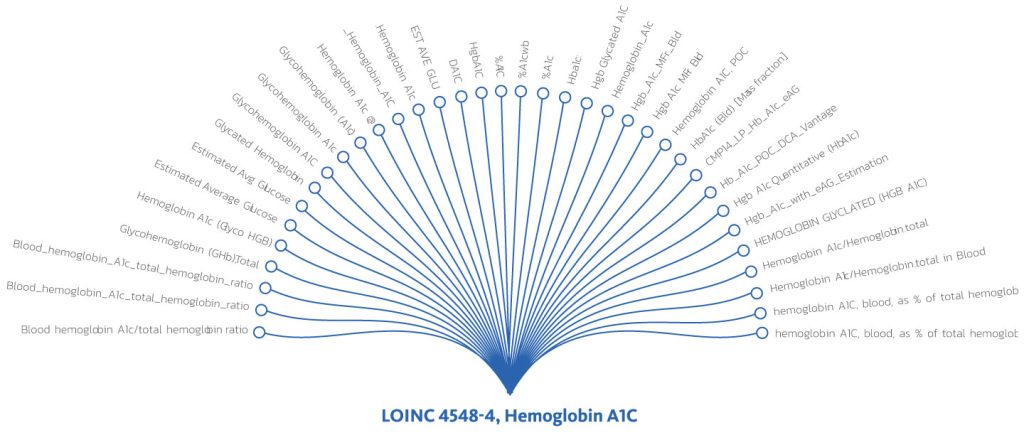
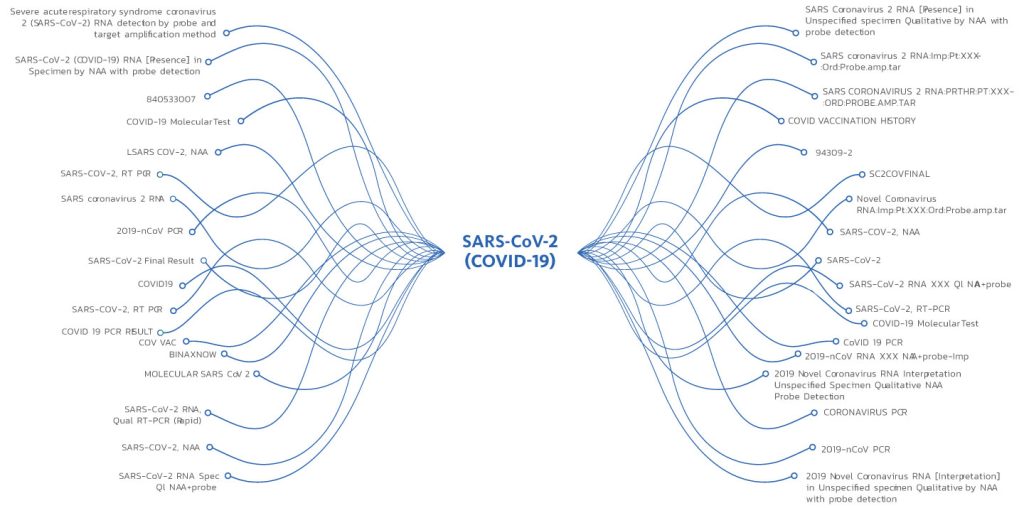
Coding inconsistencies also remain common. For example, we have found hundreds of different ways in which a single clinical data element (such as the test for hemoglobin A1c) is documented. One study of data quality reflected that 41% of HbA1c results did not use a LOINC code and instead consisted of a variety of uncoded textual input. There are 34 million diabetics in the United States, so helping them to manage their disease is critical. Imagine the magnitude of the problem extrapolated to testing for COVID-19 in the United States. The pandemic to date has infected a documented 70 million people and nearly 800 million COVID-19 tests have been performed in the United States in two years. This doesn’t even begin to address at home testing or variable reporting strategies on a state-by-state basis.
Below is an example of the wide variation in how a hemoglobin A1c (HbA1c) test might be documented in a medical record. For analytics, this data should map to a single LOINC code (LOINC 4548-4) and description.
In this example, note the wide discrepancies in both the code and descriptions for this COVID-19 test. Note that all these codes should be expressed as a single SNOMED code (260385009) and a single description (negative) for actionable analytics. This lack of standardization makes it difficult for public health departments to determine appropriate responses in a timely fashion. Automation can replace enormous investments in additional staff.
To summarize, we have identified four dimensions that present significant problems inherent to raw clinical data that impact downstream efficacy:
To tackle these challenges, certain organizations have utilized mapping technology, whereas others have employed data analysts and data scientists who work tirelessly on the ongoing task of data cleansing. These approaches are an unscalable and costly way to deal with the issue, and force analysts and data scientists to do repetitive manual work well below the top of their license. Our customers and partners have transitioned from recognizing the potential of clinical data to having the power to deploy clinical data fit-for-purpose at scale. They use Availity Fusion’s automated data transformation engine to produce upcycled data – data that is normalized to national standards, interoperable, deduplicated, consolidated into a longitudinal record, and available in fit-for-purpose data packages for flexible deployment at scale.
“Availity Fusion’s automated data transformation engine produces upcycled data – data that is normalized to national standards, interoperable, deduplicated, consolidated into a longitudinal record, and available in fit-for-purpose data packages for flexible deployment at scale.”
Upcycled data is more than just high quality, semantically normalized data. It’s a data asset that fits into an overall enterprise data acquisition and storage architecture. That means it can be flexibly integrated into any existing tech stack; integrated into data lakes and other repositories; delivered in a consumable fashion to underwriters, care coordinators, providers, and consumers via portals; served up into applications via APIs; or used as a foundation for value-added capabilities for solution providers, aggregators, HIEs, and data acquisition tools.
Availity Fusion’s real time automated data transformation technology has demonstrated that the challenges around data inconsistencies and fragmentation can be overcome. We are partnering with leading health solution vendors, national payers, HIEs, government entities, and life insurers to turn their clinical data into an asset that can be deployed across the enterprise at scale.